

Чем сети AI / ML отличаются от сетей традиционных дата-центров
Распространение искусственного интеллекта (AI) и машинного обучения (ML) стимулирует рост производительности и эффективности сетей дата-центров. В статье рассмотрены новые требования к AI сетям, отличия трафика AI / ML от трафика традиционных сетей дата-центров, а также технологии адаптации сети Ethernet для высоконагруженного AI трафика, и то, как наши решения помогают оптимизировать AI сети.
Новые требования к AI сети
Типы данных, объем и модели трафика в AI дата-центрах радикально отличаются от традиционных дата-центров, поэтому и требования к AI / ML сетям другие. Инвестиции в AI сети дата-центра могут достигать миллионов долларов. Оптимизация AI сети может существенно снизить время, требуемое для создания моделей обучения, и таким образом повысить отдачу от инвестиций.
Традиционные дата-центры
В традиционных дата-центрах обычно обрабатываются отдельные запросы пользователей или запланированные задания, в т.ч. длительные задания на ночь. Эти рабочие нагрузки могут сильно различаться, а трафик равномерно распределяется по сетевым линкам и его объем растет пропорционально числу пользователей. Если это банк, то могут быть как простые веб-запросы от банковских систем, например, баланс счета, выполняемые за доли секунды, так и более продолжительные работы по вычислению процентных ставок банка, выполняемые за ночь. Потери и задержки отдельных пакетов здесь некритичны, поскольку протокол TCP способен исправлять такие ошибки.
AI дата-центры
AI кластер в дата-центре, напротив, больше напоминает суперкомпьютер с тысячами графических процессоров (GPU) и сотнями обычных процессоров (CPU) с коммутаторами. В AI кластере все GPU работают над одной задачей по созданию и обучению большой языковой модели (LLM), что может занимать дни и недели.
Эти GPU перемещают большие массивы данных по быстрым сетевым линкам, и здесь потеря пакетов или задержка на любом из линков недопустимы, поскольку это может вызвать повторное выполнение целого этапа обучения AI сети. После создания LLM может быть перемещена в компьютерную систему front-end для предоставления услуг на базе GPU или CPU. Затем пользователи могут направлять в LLM запросы, чтобы проверить, как усвоена информация при обучении модели. Это процесс называется «инференс» (inference) – использование обученной большой языковой модели для решения практических задач с текстом: генерации, анализа, понимания и обработки информации. В этой статье рассматривается только этап обучения LLM-моделей на обслуживающих (back-end) системах.
Эти GPU перемещают большие массивы данных по быстрым сетевым линкам, и здесь потеря пакетов или задержка на любом из линков недопустимы, поскольку это может вызвать повторное выполнение целого этапа обучения AI сети. После создания LLM может быть перемещена в компьютерную систему front-end для предоставления услуг на базе GPU или CPU. Затем пользователи могут направлять в LLM запросы, чтобы проверить, как усвоена информация при обучении модели. Это процесс называется «инференс» (inference) – использование обученной большой языковой модели для решения практических задач с текстом: генерации, анализа, понимания и обработки информации. В этой статье рассматривается только этап обучения LLM-моделей на обслуживающих (back-end) системах.
Масштабирование
При масштабировании традиционного дата-центра, необходимость в оптимизации, в первую очередь, определяется путем сравнения заданного SLA времени ответа на запрос с фактическим результатом получения ответа. Результат может составлять миллисекунды в случае получения баланса расчетного счета в банке или часы для большой работы. Если результат не удовлетворяет ожиданиям по времени, оператор дата-центра может просто изменить число серверов, скорость сети или ввода данных.
Напротив, масштабирование AI кластера требует оптимизации времени на построение модели обучения, которое может занять недели и месяцы. Убыстрение процесса обучения хотя бы на несколько дней может дать миллионы долларов экономии за счет того, что следующая задача в AI сети начнет обрабатываться раньше. Здесь тоже можно просто добавить модули GPU, но это дорого, и GPU всегда в дефиците.
Напротив, масштабирование AI кластера требует оптимизации времени на построение модели обучения, которое может занять недели и месяцы. Убыстрение процесса обучения хотя бы на несколько дней может дать миллионы долларов экономии за счет того, что следующая задача в AI сети начнет обрабатываться раньше. Здесь тоже можно просто добавить модули GPU, но это дорого, и GPU всегда в дефиците.

Поэтому лучше подходить к оптимизации AI сети путем сокращения времени простоя GPU и устранения перегрузок в сети, то есть обойтись без ввода новых вычислительных мощностей.
В AI кластере все GPU работают вместе в процессе обучения модели. Любая задержка или потеря пакета на одном GPU кластера приводит к простою остальных GPU и, соответственно, к росту общего времени выполнения работы. Решать проблему только при помощи высокоскоростных сетевых линков недостаточно, хотя и это тоже необходимо. Но главный подход – это конфигурация AI сети для устранения перегрузок, что можно делать при помощи различных технологий современных сетей Ethernet.
В AI кластере все GPU работают вместе в процессе обучения модели. Любая задержка или потеря пакета на одном GPU кластера приводит к простою остальных GPU и, соответственно, к росту общего времени выполнения работы. Решать проблему только при помощи высокоскоростных сетевых линков недостаточно, хотя и это тоже необходимо. Но главный подход – это конфигурация AI сети для устранения перегрузок, что можно делать при помощи различных технологий современных сетей Ethernet.
Новые модели трафика
Природа сетевого трафика в AI дата-центрах отличается от трафика в традиционных дата-центрах. Рабочий трафик распределяется среди сотен и тысяч GPU, которые принимают и отправляют большие наборы данных. Размеры наборов данных отличаются ненамного в отличии от трафика интернет, где объемы наборов данных могут сильно различаться. В AI кластерах происходят быстрые и частые переходы от вычислений к пересылкам их результатов между модулями GPU. В перерывах между пересылкой данных и ожиданием информации GPU простаивает. Трафик может носить взрывной характер и иметь специфические модели, типа «все ко всем», когда сразу много GPU стараются послать данные друг другу, что может вызвать перегрузки линков.
«Длинный хвост»
Производительность сети AI определяется измерением потока с наибольшим временем завершения задания, а не средней полосой пропускания, как в традиционном дата-центре. Этот «длинный хвост» (см. рис. 1) существенно влияет на время завершения цикла работы, и, таким образом, на степень использования GPU. Например, если среднее время завершения задания одного GPU составляет 150 мс, а время завершения самого медленного GPU в слое нейросети – 190 мс, то и среднее время обработки этапа задания будет 190 мс.
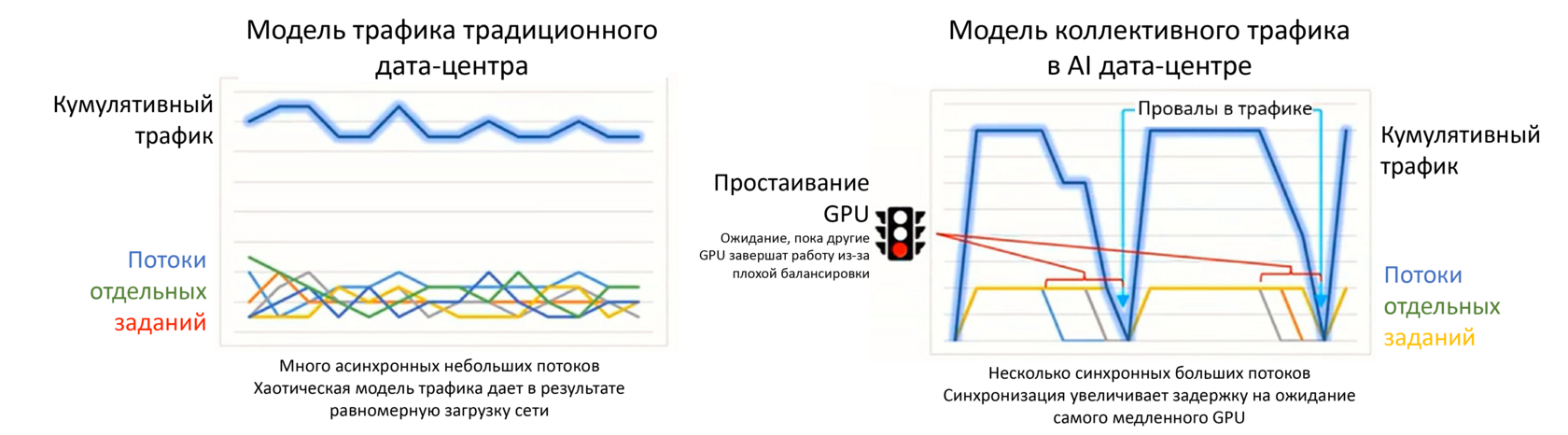
Рис. 1. Модель равномерной загрузки трафика традиционного дата-центра и «хвостатого трафика» AI дата-центра (источник: Cisco)
Для оптимизации сети важна балансировка
В примере выше некоторые GPU получают данные много быстрее других. Цель оптимизации – не в том, чтобы достичь самого быстрого перемещения данных к определенному GPU, а в том, чтобы достичь такой балансировки сети, при которой все GPU получали бы данные примерно в одно время. При балансировке медленные потоки ускоряются, а быстрые – замедляются. Как только все GPU обменяются данными, они одновременно могут начать следующий цикл вычислений. Такая оптимизированная сеть дает максимально возможное использование массива GPU в AI кластере.
Можно привести такую аналогию. Если 100 шариков подвесить над сеткой с отверстиями, которые немного больше шариков, и одновременно отпустить все шарики, многие из них очень быстро провалятся в свои отверстия в сетке, но некоторые соберутся в кучу, и потребуется некоторое время, чтобы провалился последний. Если направлять шарики по каким-то рукавам к отверстиям, все шарики пройдут почти одновременно, даже если первому шарику потребуется больше времени, чтобы пройти сквозь свое отверстие в сетке. Отверстия здесь – это сетевые линки, а шарики – это потоки данных от GPU.
В целом, можно сказать, что в традиционных дата-центрах обрабатывается много потоков с разным объемом трафика в разное время для разных клиентов. Балансировка такого типа трафика – сравнительно простая задача, и в некоторых случаях такой трафик сам себя балансирует. С другой стороны, трафик AI состоит из массивных потоков, проходящих все время ко всем узлам, и такой трафик балансировать гораздо сложнее.
Можно привести такую аналогию. Если 100 шариков подвесить над сеткой с отверстиями, которые немного больше шариков, и одновременно отпустить все шарики, многие из них очень быстро провалятся в свои отверстия в сетке, но некоторые соберутся в кучу, и потребуется некоторое время, чтобы провалился последний. Если направлять шарики по каким-то рукавам к отверстиям, все шарики пройдут почти одновременно, даже если первому шарику потребуется больше времени, чтобы пройти сквозь свое отверстие в сетке. Отверстия здесь – это сетевые линки, а шарики – это потоки данных от GPU.
В целом, можно сказать, что в традиционных дата-центрах обрабатывается много потоков с разным объемом трафика в разное время для разных клиентов. Балансировка такого типа трафика – сравнительно простая задача, и в некоторых случаях такой трафик сам себя балансирует. С другой стороны, трафик AI состоит из массивных потоков, проходящих все время ко всем узлам, и такой трафик балансировать гораздо сложнее.
Когда делать апгрейд AI сети? Смена парадигмы
В традиционных дата-центрах, когда загрузка линка достигает 50%, настает время увеличивать количество линков. Однако, в AI дата-центрах линки обычно загружены на 90%. Если даже каким-то волшебным образом количество линков удвоить, то все равно их загрузка останется очень высокой.
Новые конфигурации сетей Ethernet
В современных дата-центрах сети строятся на основе технологии Ethernet, и операторы дата-центров могут оптимизировать и изменить их конфигурацию для поддержки AI сетей. Это можно сделать собственными ресурсами компании при наличии у персонала достаточной квалификации, а можно обратиться к внешним контракторам или консультантам.
Современные протоколы Ethernet для управления потоками и перегрузками трафика в дата-центрах используют такие технологии как управление приоритетными потоками PFC (priority flow control), явное уведомление о перегрузке ECN (explicit congestion notification), квантизированное уведомление о перегрузке дата-центра DCQCN (data center quantized congestion notification), а также веерная рассылка пакетов (packet spraying). Давайте рассмотрим эти технологии.
Современные протоколы Ethernet для управления потоками и перегрузками трафика в дата-центрах используют такие технологии как управление приоритетными потоками PFC (priority flow control), явное уведомление о перегрузке ECN (explicit congestion notification), квантизированное уведомление о перегрузке дата-центра DCQCN (data center quantized congestion notification), а также веерная рассылка пакетов (packet spraying). Давайте рассмотрим эти технологии.
Начинаем настройку с PFC и ECN
Когда буфер коммутатора наполняется до определенного порога, PFC дает возможность коммутатору послать кадр паузы в устройство, откуда приходит поток, останавливая трафик в этой очереди. Хотя этот подход устраняет потерю пакетов, само по себе это не очень хорошее решение. Работа сети при этом замедляется, очереди пакетов то идут, то стоят.
ECN выдает извещение о перегрузке между устройствами, при этом посылающее устройство просто снижает скорость трафика.
Как ECN, так и PFC хорошо справляются с управлением перегрузкой по отдельности, но их совокупная эффективность превосходит индивидуальную производительность. ECN реагирует в первую очередь, чтобы уменьшить перегрузку, в то время как PFC действует как отказоустойчивый механизм, предотвращая падение трафика, если ответ ECN задерживается и увеличивается использование буфера. Этот совместный подход к управлению перегрузкой известен как Data Center Quantized Congestion Notification (DCQCN), разработанный для сетей RoCE (см. ниже).
DCQCN – алгоритм, который координирует работу ECN и PFC и дает возможность ECN управлять потоком, снижая скорость передачи при наступлении перегрузки, таким образом, активность PFC снижается. Настройка DCQCN – сложная задача, но есть и другие пути усовершенствования конфигурации AI.
ECN выдает извещение о перегрузке между устройствами, при этом посылающее устройство просто снижает скорость трафика.
Как ECN, так и PFC хорошо справляются с управлением перегрузкой по отдельности, но их совокупная эффективность превосходит индивидуальную производительность. ECN реагирует в первую очередь, чтобы уменьшить перегрузку, в то время как PFC действует как отказоустойчивый механизм, предотвращая падение трафика, если ответ ECN задерживается и увеличивается использование буфера. Этот совместный подход к управлению перегрузкой известен как Data Center Quantized Congestion Notification (DCQCN), разработанный для сетей RoCE (см. ниже).
DCQCN – алгоритм, который координирует работу ECN и PFC и дает возможность ECN управлять потоком, снижая скорость передачи при наступлении перегрузки, таким образом, активность PFC снижается. Настройка DCQCN – сложная задача, но есть и другие пути усовершенствования конфигурации AI.
Решение IXIA
Тестирование сетевой фабрики AI
(RoCEv2)
(RoCEv2)
IXIA Network Emulator 3
Тестирование приложений и решений ИБ в масштабах предприятия
Дальнейшие варианты оптимизации
Маршрутизация по равноценным линкам ECMP (Equal cost multipath) – это стратегия маршрутизации, которая используется в традиционных дата-центрах для балансировки потоков в сети. Однако, если один поток AI полностью занимает линк, такой подход проблематичен. Для сети AI более эффективна балансировка сети на уровне пакетов.
При веерной рассылке пакетов (packet spraying) и других видах балансировки нагрузки, таких как динамическая балансировка нагрузки (dynamic load balancing), маршрутизация по ячейкам (cell-based routing) и когнитивная маршрутизация (cognitive routing), происходит пересылка пакетов через доступные сетевые линки. Пакеты по размерам меньше чем потоки в коллективе AI, и при этом загрузка линка существенно лучше.
При веерной рассылке пакетов (packet spraying) и других видах балансировки нагрузки, таких как динамическая балансировка нагрузки (dynamic load balancing), маршрутизация по ячейкам (cell-based routing) и когнитивная маршрутизация (cognitive routing), происходит пересылка пакетов через доступные сетевые линки. Пакеты по размерам меньше чем потоки в коллективе AI, и при этом загрузка линка существенно лучше.
Сделайте шаг к профессиональному
и удобному тестированию!
и удобному тестированию!
Оставить заявку
на консультацию
На уровне оборудования технология удаленного прямого доступа к памяти RDMA (Remote Direct Memory Access) позволяет приложениям, работающим на двух серверах, обмениваться данными напрямую без использования других процессоров, операционных систем, кеш-памяти или сетевого ядра. То есть приложение может считывать или записывать данные в память другого сервера без использования процессора этого сервера, поэтому данные перемещаются быстрее и с низкой задержкой. Технология RoCE (RDMA over Converged Ethernet) реализует этот механизм в сетях Ethernet.
Сеть Ethernet без потерь
Путем комбинации этих технологий с соответствующими настройками можно создать сеть Ethernet без потерь.
Существуют протоколы для сети Ethernet без потерь, как и инструменты для измерения результатов, а также приложения управления вкупе с квалификацией сетевых инженеров и архитекторов. Эксперты отрасли разрабатывают новые возможности для Ethernet, как и инновации для AI. Организация Ultra Ethernet Consortium работает над стандартизацией функций повышения производительности Ethernet и над упрощением конфигураций и управления сетью, как части «дорожной карты» развития сетей AI.
Проблема в том, как протестировать соответствие дизайна сети и поставленных целей.
Существуют протоколы для сети Ethernet без потерь, как и инструменты для измерения результатов, а также приложения управления вкупе с квалификацией сетевых инженеров и архитекторов. Эксперты отрасли разрабатывают новые возможности для Ethernet, как и инновации для AI. Организация Ultra Ethernet Consortium работает над стандартизацией функций повышения производительности Ethernet и над упрощением конфигураций и управления сетью, как части «дорожной карты» развития сетей AI.
Проблема в том, как протестировать соответствие дизайна сети и поставленных целей.
Новые способы оптимизации AI сетей
Тестирование сетей AI требует создания моделей трафика, который наблюдается в течение обучения AI и посылки этих данных через сеть от генератора трафика, который эмулирует GPU и сетевые карты RDMA (NIC). GPU поддерживают сетевые карты RDMA, которые быстро пересылают данные между GPU.
Типы трафика для эмуляции
Система тестирования должна воспроизводить сценарии с различными моделями и размерами данных, которые имеют место в AI кластере. Трафик включает эмулированные соединения и потоки пар очередей (Q-pair), генерацию уведомлений о перегрузке линков, а также система должна уметь динамически управлять скоростью передачи с использованием DCQCN. Кроме того, она должна уметь гибко тестировать пропускную способность, управлять буфером и выполнять ECMP хеширование.

Рис. 2. AI кластер и решение IXIA для тестирования сетевой фабрики AI с генератором трафика AresONE
Для улучшения дизайна сети можно использовать генераторы трафика с поддержкой RoCEv2 / RDMA в лаборатории или тестовой зоне. Таким образом можно измерить производительность платформы AI без использования ускорителей GPU.
Эффективное решение для оптимизации AI сетей должно обеспечивать гибкость определения системной конфигурации AI для соответствующей рабочей нагрузки. Такая конфигурация включает число GPU, сетевых карт NIC, настройки управления перегрузками (например, PFC и DCQCN), размеры данных, характеристики пар очередей (Q-pair), и конфигурацию эмулируемой NIC. Такая гибкость позволяет производить тестирование самых различных конфигураций эффективным и надежно повторяемым образом.
При тестировании важно проводить прогоны данных различных размеров, получая результаты таких основных показателей, как время завершения, алгоритм, полоса пропускания шины. Крайне важно также проводить статистический анализ распределения этих метрик среди индивидуальных Q-пар RoCEv2.
Эффективное решение для оптимизации AI сетей должно обеспечивать гибкость определения системной конфигурации AI для соответствующей рабочей нагрузки. Такая конфигурация включает число GPU, сетевых карт NIC, настройки управления перегрузками (например, PFC и DCQCN), размеры данных, характеристики пар очередей (Q-pair), и конфигурацию эмулируемой NIC. Такая гибкость позволяет производить тестирование самых различных конфигураций эффективным и надежно повторяемым образом.
При тестировании важно проводить прогоны данных различных размеров, получая результаты таких основных показателей, как время завершения, алгоритм, полоса пропускания шины. Крайне важно также проводить статистический анализ распределения этих метрик среди индивидуальных Q-пар RoCEv2.
Заключение
Требования к сети и модели трафика AI дата-центра сильно отличаются от традиционных дата-центров. Различными методами можно оптимизировать AI сеть, чтобы максимально использовать ее емкость. Одна из ключевых стратегий оптимизации сети заключается в повышении степени использования GPU. Хотя существует много способов сделать это, настраивая протоколы сети Ethernet, эти способы отнюдь не очевидны или тривиальны.
Чтобы избежать ручной работы, занимающей много времени, можно использовать инструменты тестирования для выявления параметров AI сети и их оптимизации. Имея эти параметры, сетевые архитекторы могут использовать решение IXIA для тестирования сетевой фабрики AI для эмуляции сетевой нагрузки и поведения GPU, чтобы заранее найти «узкие места» и оптимизировать параметры сети. В комбинации с нагрузочными тестовыми модулями, это решение оптимизирует AI сеть, в результате чего улучшается степень использования GPU, т.е. минимизируются потери ресурсов и сокращаются затраты на создание сети GPU.
Чтобы избежать ручной работы, занимающей много времени, можно использовать инструменты тестирования для выявления параметров AI сети и их оптимизации. Имея эти параметры, сетевые архитекторы могут использовать решение IXIA для тестирования сетевой фабрики AI для эмуляции сетевой нагрузки и поведения GPU, чтобы заранее найти «узкие места» и оптимизировать параметры сети. В комбинации с нагрузочными тестовыми модулями, это решение оптимизирует AI сеть, в результате чего улучшается степень использования GPU, т.е. минимизируются потери ресурсов и сокращаются затраты на создание сети GPU.
Решение IXIA UHD100T32
Тестирование приложений и решений ИБ в масштабах предприятия
Решение IXIA UHD400T
Ultra-high Density
Тестирование приложений и решений ИБ в масштабах предприятия
Решение IXIA AresONE-M 800GE
Тестирование приложений и решений ИБ в масштабах предприятия
РУТЕСТ
Почему стоит выбрать РУТЕСТ для тестирования
-

Комплексный подход
Мы охватываем все аспекты тестирования, включая методологии, аренду решений и автоматизацию -
Опыт и профессионализм
Мы работаем с передовыми технологиями и знаем, как внедрить их в ваш бизнес -
Экономия времени и ресурсов
Наши услуги позволяют снизить затраты на тестирование, сохраняя высокое качество
